Markdown でメモを取り続けていると、「雑に残したい」と「あとで見返したい」がぶつかりやすくなります。特に止まりやすいのは、「この思考や実行ログをどこへ置くか」を入力時に毎回判断しなければいけないときです。
整理しながら書こうとすると手が止まり、雑に書くと後から探せなくなります。この2つを同時に満たそうとして失敗するなら、入力と整理を最初から分けてしまったほうが運用は安定します。
この記事では、その問題に対して raw / conformed / consumption の3層に分けたうえで、AIエディタ上のコマンドと運用用プロンプトを組み合わせ、どう回る形にしたかをまとめます。ファイル構造だけでなく、整理済み知識を見返す viewer や、記事単位の作業ディレクトリまで含めて、「設計だけで終わらず実際に使える状態」にした流れを紹介します。
想定読者とこの記事のポイント
この構成は、次のような人に向いています。
- Markdown でメモを取っているが、蓄積するほど見返しにくくなっている
- きれいに書こうとしてログが止まりがち
- 個人ナレッジをローカルで運用しつつ、あとで記事化にもつなげたい
この記事のポイントは次の通りです。
raw / conformed / consumptionの3層に分けると、「残す」と「使う」を分離しやすい- 3層構造だけでなく、AIエディタ上のコマンド運用まで含めて初めて回る
conformed/_index.yamlを正本にすると、検索・自動処理・viewer の基点を1つに寄せられる- viewer と
consumptionの作業ディレクトリまで揃えると、整理した知識が実際に使える状態になる
結論:3層構造と運用を分けると止まりにくい
結論から言うと、ログを1か所に押し込めるのではなく、役割ごとに3層へ分けると運用しやすくなります。ポイントは、きれいに整理された入力を目指すことではなく、入力時の判断を極力減らし、その後の整形を AIエディタ側の運用へ委ねることです。
raw- 思考や会話、作業メモ、画像を止めずに残す場所
conformed- 後から使える形へ整理する場所
consumption- 記事化や発信準備のための作業ディレクトリ
この3層は、ファイル構造だけで勝手に回るわけではありません。実際には、各層の間に専用プロンプトを置くことで、「人間がどこまでやるか」と「AI がどこから整理するか」を明確に切り分けています。
ここでいう /xxxx は、AIエディタ上で自分で定義して使うコマンドです。コマンドが呼ばれたときに、裏側でどの prompt を読んで、どんな振る舞いをするかを決めています。見えているのは短いコマンド名ですが、実体は runtime/ に置いた運用用プロンプトです。
さらに、conformed/_index.yaml を正本にすると、viewer や記事化フローの基点を1つに寄せられます。設計だけで終わらせず、実際に見返せる UI と、記事候補ごとに 参照元まとめ.md / ドラフト.md / 必要なものリスト.md を持つ作業ディレクトリまで揃えることで、「整理したつもりで終わる」状態を避けやすくなります。
実際のディレクトリ構成
まずは、実際のファイル構成を見ると、3層の分け方がかなりイメージしやすくなります。今回の運用では、raw に入れた内容が、AIエディタ上のプロンプトを経由して conformed へ整理され、最終的に consumption の記事作業ディレクトリへ流れています。
logbook/
├── docs/
├── runtime/
│ ├── prompt_raw.md
│ ├── prompt_conformed.md
│ ├── prompt_consumption.md
│ └── web_article_guide.md
├── raw/
│ ├── active/
│ ├── archive/YYYY/
│ └── index.md
├── conformed/
│ ├── _index.yaml
│ ├── decisions/
│ ├── backlog/
│ ├── reference/
│ └── howto/
└── consumption/
├── draft-web/
│ └── logbook_file_structure/
│ ├── 参照元まとめ.md
│ ├── ドラフト.md
│ └── 必要なものリスト.md
└── _index.yaml
ポイントは、思考を止めずに残す raw、あとから再利用できる形にする conformed、発信や記事化の準備をする consumption を分けていることです。これで「今は雑に残したい」と「後で使いたい」の衝突を減らしやすくなります。
AIエディタ上の基本フロー
この logbook が普通のフォルダ設計と違うのは、AIエディタ上で回す運用まで含めて設計しているところです。基本フローは次の通りです。
raw/active/YYYYMMDD_topic.mdを作る/logbook-chatで raw に追記する/logbook-conformでconformedに整理する/logbook-consumptionで記事候補をconsumptionに持ち上げる
実際の役割分担はかなり明確です。
| コマンド | 実体 | いちばん大事な役割 |
|---|---|---|
/logbook-chat |
runtime/prompt_raw.md |
raw に対話を末尾追記する |
/logbook-conform |
runtime/prompt_conformed.md |
raw を読み、conformed に整理して書き出す |
/logbook-consumption |
runtime/prompt_consumption.md |
conformed/_index.yaml を起点に記事素材ディレクトリを作る |
この分担のおかげで、人間側の仕事は「まず raw に入れる」までに圧縮できます。AI に任せる範囲が prompt 単位で分かれているので、入力時に細かい分類をその場で考えなくて済みます。
prompt が何を保証しているか
役割だけでなく、prompt の中身もかなり明示的です。全文を貼ると長すぎるので、ここでは「その prompt が何を保証しているか」が分かる部分だけに絞ります。
/logbook-chat の核は次の通りです。
* 対象ファイル(現在開いている `.md`)を読み取る
* 文脈を理解する
* **末尾に追記する**
* 既存の内容は絶対に編集しない
* 必ず「追記」のみ行う
/logbook-conform の核は、raw を4タイプへ分類して conformed に書き出すことです。もちろん完全に網羅的な分類ではありませんが、設計の確定、外部知識、未確定の着想、再現可能な手順の4つがあれば、個人ログの多くはひとまず受け止めやすくなります。
| decision | 意思決定・設計の確定・方針 | `decisions/{sub}/{theme_id}/current.md` |
| reference | 外部知識・調査結果・出典あり | `reference/{sub}/{theme_id}.md` |
| backlog | 着想・「いつかやりたい」・未確定 | `backlog/{sub}/{theme_id}.md` |
| howto | 再現可能な手順・固まった操作方法 | `howto/{sub}/{theme_id}.md` |
/logbook-consumption の核は、「記事候補を見つける」ことよりも、「記事化に進めるための作業ディレクトリを作る」ことです。
* `conformed/_index.yaml` を読む
* 記事候補ごとに `consumption/draft-web/{theme_id}/` を作る
* `参照元まとめ.md` / `ドラフト.md` / `必要なものリスト.md` の3ファイルを揃える
* `web_article_guide.md` に従って、公開記事に近いドラフトを作る
さらに、このコマンドでは候補ごとに 参照元まとめ.md / ドラフト.md / 必要なものリスト.md の3ファイルを揃える、という作業単位まで決まっています。加えて、web_article_guide.md を読むことで、抽象説明だけで終わらせないこと、実例や画面を理屈より先に置くこと、不足素材をごまかさないことまで含めて品質方針が固定されています。つまり、「AI にいい感じで整理してもらう」のではなく、「どの段階で何を作り、そのときどんな品質で書くか」がかなり具体的に決まっています。
raw は雑でよく、conformed には成果だけを残す
この設計の価値は、整理前後を並べるとさらに分かりやすくなります。実際の raw では、かなりラフな相談から始まっています。
## user
自分のローカルのファイルについて、
- なにも考えずにフラットにログを貯められて
- 参照とか探すときには、効率よく探せて
- AIエディタにぶん投げて、web記事かもできる
ようにしたい
そのため、このrawを、カテゴリとかにきれいに振り分けるといいのかなとは思います
(conformedレイヤ的な感じ)
ここで重要なのは、会話や検討の流れを raw にそのまま残していることです。この段階で整理しようとすると、入力の勢いが止まりやすくなります。
一方、conformed では「結果だけ」を抽出します。
## レイヤ構成
| レイヤ | 目的 | 更新方式 |
| --- | --- | --- |
| **raw** | 追記専用の時系列ログ。会話・思考をそのまま記録。 | 追記のみ(編集禁止) |
| **conformed** | raw を整理・参照しやすい形に変換した知識ストア。AI が自動作成・更新。 | カテゴリ別ルール参照 |
| **consumption** | 記事化のための作業ファイル群。conformed を元に記事化。 | 追記 + status 更新 |
この変換があることで、「雑に残したメモ」が、あとから検索・再利用しやすい知識へ変わっていきます。最初から正しい置き場所を選ばなくてよいことが、実運用ではかなり効きます。
さらに、/logbook-chat で実際に AI が raw に追記している断片を見ると、この運用が「あとで整理する前提の対話ログ」だと分かります。
## user
いいかんじにできてそう、
まだやってないからわからないけど、、、
conformedのほうについては、毎回active全走査だとファイル数がおおすぎます
なので、rawと同様にactive_state.yamlを利用するのがいいと思います
## 🤖 assistant
賛成。`archive_state.md`(単一の日付文字列)を廃止して、`active_state.yaml` に統合する。
ここで大事なのは、AI が会話の返答を raw にそのまま追記していて、元の user ログを直していないことです。まずは対話を止めずに積み、整理や構造化は後段の /logbook-conform に回します。
conformed/_index.yaml を正本にする意味
conformed 側では、ファイル群をそのまま読むのではなく、_index.yaml を正本にしています。実際のエントリは次のような形です。
- filename: "decisions/dev/logbook_file_structure/current.md"
type: decision
source_raw:
- "raw/active/20260418_ファイル構造構想.md"
- "raw/active/20260419_ファイル構造構想_続き.md"
category:
sub: dev
theme_id: logbook_file_structure
theme: logbookファイル構造設計
status: reviewed
summary: 0000_logbook の raw/conformed/consumption 3層構成・prompt運用・index.yaml 設計をまとめた確定版。
この形にしておくと、「何の情報か」と「どこにあるか」を分けて扱えるので、viewer や自動処理の基点を1つに寄せやすくなります。filename は実ファイルを指し、type や category は意味づけを持つため、ファイル走査よりも索引中心で運用を組み立てやすくなります。
この設計の利点をまとめると次の通りです。
- viewer が一覧や filter を作る基点を1つに寄せられる
source_rawで元ログへの導線を保てるconsumptionへの記事候補生成でも同じ索引を使い回せる- 実ファイルの配置と、意味づけの情報を分けて扱える
consumption を別層にする理由
さらに、consumption 側を {theme_id} ごとの作業ディレクトリにしたことで、記事化の下準備も分かりやすくなりました。
consumption/draft-web/logbook_file_structure/
├── 参照元まとめ.md
├── ドラフト.md
└── 必要なものリスト.md
この分け方にすると、参照元の集約、本文ドラフト、不足素材の管理を1ファイルに押し込めずに済みます。consumption は公開本文そのものではなく、「記事化に進めるための作業場」と割り切ったほうが運用しやすいです。
そして、この consumption の生成自体も AIエディタ上のプロンプトで回します。prompt_consumption.md では、記事候補ごとに 3 ファイルを揃えることに加えて、web_article_guide.md に従って公開記事に近いドラフトを作るところまで役割が決まっています。この記事で扱っているのは、単なるフォルダ案ではなく、「AI にどこまでやらせるか」を明文化した運用仕様でもあります。
ところで、整理した知識をどう見返すのか
ここまでで、入力、整理、記事化準備の流れは作れます。ただ、整理したファイルが増えるだけでは、あとから参照するコストはまだ高いままです。そこで、この logbook では閲覧用の UI も用意しています。
この UI でできることは、だいたい次の通りです。
- 一覧を見る
- filter で絞り込む
- 詳細 preview を読む
- 元の raw への参照をたどる
- Markdown 内のローカル画像を見る
流れとしては、まず conformed/_index.yaml を読み、そこから一覧を作り、条件で絞り込み、選んだエントリの詳細を表示する形です。Markdown ファイル群を1つずつ人間が探さなくても、索引をもとに入口をまとめて作れます。
この UI 自体も、最初から手で細かく作り込んだというより、やりたい体験を AIエディタに渡して、やり取りしながら形にしていったものです。最初の相談では、
conformedが増えると自分で探すのは難しそうconformed/_index.yamlを読みたい- Notion の table view のように見たい
- タグなどで filter をかけたい
- クリックしたものを横や下で preview したい
といった要件が先に出ていました。
その後、実際に UI ができてからは、
- テーブルが狭くて見づらい
- preview は残したい
- preview で画像も見たい
という追加のフィードバックを返して、改善を重ねています。ここでも大事なのは、コードの書き方そのものより、どんな体験を作りたいかを先に言語化していたことでした。
実際の画面はこんな感じです。
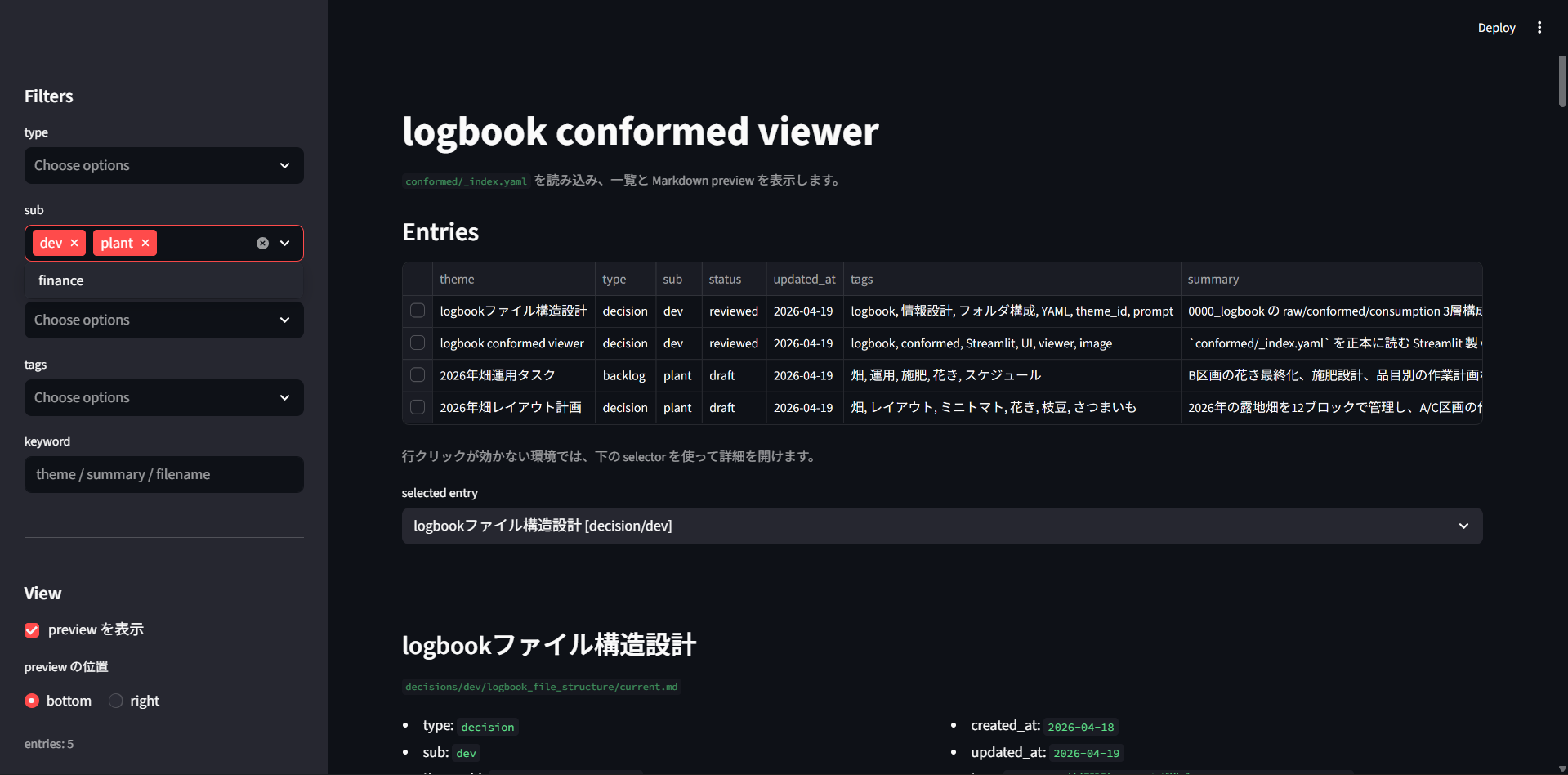
左に filter、中央に一覧、下に preview が見えていて、conformed/_index.yaml を正本にした閲覧導線がそのまま UI になっています。この1枚があるだけで、「整理した知識を見返せる状態まで作っている」ことがかなり伝わりやすくなります。
まとめ
raw / conformed / consumption の3層に分けると、思考を止めずに残しながら、後で使える形にも育てやすくなります。特に効いているのは、「どこに入れるか」を入力時に悩まなくてよくなることです。まずは raw に入れ、後から conformed と consumption に回すだけでも、運用はかなり軽くなります。
ただし、本当に回る理由は3層構造そのものより、AIエディタ上でそれぞれを動かすプロンプトが揃っていることです。raw への追記、conformed への知識化、consumption への記事ドラフト化が分かれているから、人間は入力だけに寄せやすくなります。
さらに conformed/_index.yaml を正本にして viewer まで作ると、整理した知識を実際に見返して使う導線ができます。その先に consumption の記事作業ディレクトリまで置くと、「残しただけ」で終わらず、発信準備まで自然につながります。
次に試すなら、まずは raw と conformed の役割を明確に分け、そのあとで _index.yaml を読める viewer や一覧画面を足す流れが取り入れやすそうです。